%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Depth Estimation
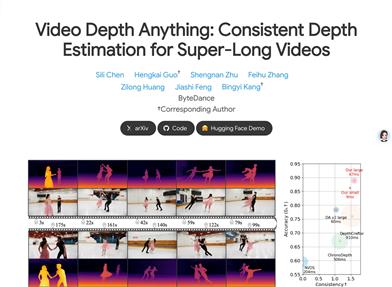
Video Depth Anything
Video Depth Anything is a deep learning-based video depth estimation model capable of providing high-quality and temporally consistent depth estimates for super-long videos. This technology is developed based on Depth Anything V2, boasting strong generalization capabilities and stability. Its primary advantages include the ability to estimate depth for any length of video, temporal consistency, and adaptability to open-world video. The model was developed by ByteDance's research team to address challenges in depth estimation for long videos, such as temporal consistency and adaptability in complex scenes. The code and demos for this model are currently available for researchers and developers.
Video Editing
62.1K

Stereocrafter
StereoCrafter is an innovative framework that employs foundational models as priors, utilizing depth estimation and stereo video reconstruction techniques to transform 2D videos into immersive stereo 3D experiences. This technology overcomes the limitations of traditional methods, enhancing the high-fidelity generation performance required by display devices. Key advantages of StereoCrafter include its ability to process video inputs of varying lengths and resolutions, as well as optimizing video processing through autoregressive strategies and chunk processing. Additionally, StereoCrafter has developed complex data processing workflows to reconstruct large-scale, high-quality datasets that support the training process. This framework provides practical solutions for creating immersive content for 3D devices such as Apple Vision Pro and 3D monitors, potentially revolutionizing how we experience digital media.
Video Production
67.1K
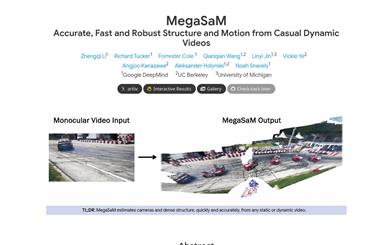
Megasam
MegaSaM is a system that allows for accurate, rapid, and robust estimation of camera parameters and depth maps from monocular videos of dynamic scenes. This system overcomes the limitations of traditional structure-from-motion and monocular SLAM techniques, which typically assume that the input videos primarily contain static scenes with significant parallax. MegaSaM can be extended to videos of complex dynamic scenes in the real world, including those with unknown fields of view and unconstrained camera paths, through carefully modified depth-visual SLAM frameworks. Extensive experiments on both synthetic and real videos demonstrate that MegaSaM is more accurate and robust in camera pose and depth estimation while being faster or comparable in runtime to previous and concurrent work.
3D Modeling
56.0K
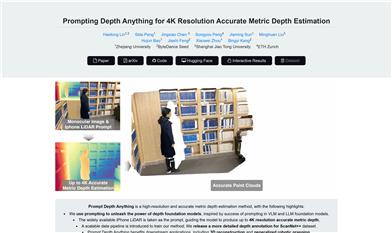
Prompt Depth Anything
Prompt Depth Anything is a method for high-resolution and high-precision depth estimation. This method unlocks the potential of depth foundational models through prompting techniques, using iPhone LiDAR as a cue to guide the model in generating precise depth measurements of up to 4K resolution. Additionally, it introduces a scalable data pipeline for training and has released a more detailed ScanNet++ dataset with depth annotations. The main advantages of this technology include high-resolution and high-precision depth estimation, along with benefits for downstream applications such as 3D reconstruction and generalized robotic grasping.
3D Modeling
50.8K
Depth Pro
Depth Pro is a research project for monocular depth estimation that can rapidly generate high-precision depth maps. This model utilizes multi-scale visual transformers for dense predictions and trains on both real and synthetic datasets to achieve high accuracy and detail capture. It generates a 2.25 million pixel depth map on standard GPUs in just 0.3 seconds, making it fast and precise, highly significant for fields such as machine vision and augmented reality.
AI image generation
56.3K
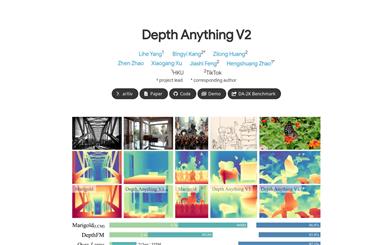
Depth Anything V2
Depth Anything V2 is an improved monocular depth estimation model. Trained using synthetic images and a large amount of unlabeled real images, it provides more refined and robust depth predictions compared to the previous version. The model demonstrates significant improvements in both efficiency and accuracy, with a speed that is over 10 times faster than the latest Stable Diffusion-based models.
AI image generation
104.3K
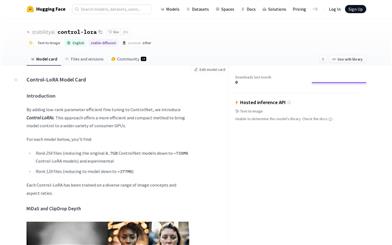
Control LoRA
Control-LoRA utilizes low-rank parameter optimization added to ControlNet, providing a more efficient and compact model control method for consumer-grade GPUs. This product includes multiple Control-LoRA models, featuring capabilities such as MiDaS and ClipDrop depth estimation, Canny edge detection, photo and sketch coloring, and Revision. The Control-LoRA models are trained to generate high-quality images across diverse image concepts and aspect ratios.
AI image generation
62.7K
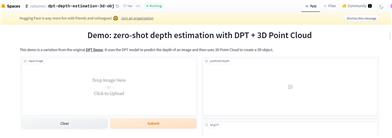
Dpt Depth
Dpt Depth is an image processing tool based on Dpt depth estimation and 3D technology. It can quickly estimate depth information from input images and generate corresponding 3D models based on the depth information. Dpt Depth Estimation + 3D is powerful and easy to use, and can be widely used in computer vision, image processing and other fields. The product offers a free trial version and a paid subscription version.
AI Image Processing
144.3K
Featured AI Tools
Chinese Picks

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
145.7K
Fresh Picks

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
111.0K
English Picks

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
127.5K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
99.1K
English Picks

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
63.8K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
89.1K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
660.5K
Chinese Picks

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M